|
Dejan Stosic1, Saša Marjanović2, Aleksandra Miletic1
1 CLLE, Université de Toulouse, CNRS, Toulouse, France
2 Faculté de philologie de l’Université de Belgrade, Serbie
Corpus parallèle ParCoLab et lexicographie bilingue français-serbe : recherches et applications

ParCoLab
http://parcolab.univ-tlse2.fr/
Résumé : Le texte présente une dynamique d’échanges scientifiques et pédagogiques entre plusieurs universités françaises et une université serbe autour d’un corpus parallèle français-serbe-anglais (ParCoLab). Il s’agit d’une nouvelle ressource textuelle disponible en ligne depuis 2015, qui a déjà donné lieu à des applications dans le domaine du traitement automatique des langues et dans l’enseignement du français et du serbe aux étrangers. La présente contribution fait état d’un nouveau type d’application dans le domaine de la lexicographie bilingue français-serbe, en prenant pour l’objet des locutions prépositionnelles en français.
Mots clés : corpus parallèle, lexicographie, coopération scientifique, locutions prépositionnelles.
Dans cette contribution[1], nous faisons état d’une nouvelle forme de relations franco-serbes qui se sont tissées entre plusieurs universités françaises et une université serbe autour d’un projet scientifique pluridisciplinaire, à visée applicative. En effet, depuis une bonne dizaine d’années, une dynamique originale est mise en place autour d’un projet de constitution d’un corpus parallèle français-serbe-anglais, réunissant des enseignants-chercheurs et étudiants, linguistes, spécialistes de traitement automatique de langue, lexicographes. De nombreux travaux et échanges scientifiques et pédagogiques bilatéraux (institutionnellement soutenus) ont donné lieu à la production d’une ressource textuelle électronique, intitulée ParCoLab, disponible pour consultation en accès libre sur Internet depuis 2015. Comportant actuellement plus de onze millions de mots dans les trois langues, issus de textes littéraires, juridiques, journalistiques et de la langue parlée, le corpus parallèle ParCoLab est devenu une source de données exploitable non seulement en linguistique et littérature descriptives comparées, mais aussi dans le domaine de l’enseignement du français et du serbe langues étrangères, du traitement automatique du serbe, de la traduction humaine ou assistée par ordinateur, ou encore dans le domaine de la lexicographie. Dans notre contribution, nous retiendrons ce dernier domaine d’application et montrerons quelques-uns des apports possibles de cette nouvelle ressource électronique dans la fabrication de dictionnaires bilingues français-serbe, plus complets, modernes et soucieux de répondre aux attentes et exigences des utilisateurs à l’ère du numérique.
L’article s’organise en trois grandes parties. Tout d’abord, nous posons l’arrière-plan institutionnel et scientifique en retraçant l’historique de la collaboration entre des universités françaises et serbes à l’origine du projet de constitution d’un corpus parallèle français-serbe-anglais (§ 1). Ensuite, nous présentons la ressource textuelle électronique ParCoLab : son contenu, sa taille et les fonctionnalités qu’elle offre aux utilisateurs (§ 2). Enfin, nous montrons les apports possibles du corpus parallèle ParCoLab dans le domaine de la lexicographie bilingue (§ 3).
1. Genèse du projet
La deuxième moitié du XXe siècle a été marquée, entre autres, par le développement de grandes bases de données textuelles électroniques pour de nombreuses langues, comme BNC pour l’anglais (cf. Leech, 1992 ; http://www.natcorp.ox.ac.uk/), Frantext pour le français (cf. Bernard et al. 2002 ; http://www.frantext.fr), CNC pour le tchèque (cf. Kucera 2002 ; www.korpus.cz), etc. L’apparition de ces ressources électroniques, comportant des dizaines de millions de mots, a profondément bouleversé les méthodes de collecte de données en sciences du langage, facilitant considérablement l’accès au matériau linguistique indispensable pour l’analyse de faits de langue. Une voie inédite s’ouvrait ainsi à de nouvelles approches, plus empiriques, dans le domaine de la linguistique descriptive.
A partir de la fin des années quatre-vingts du siècle dernier apparaît un nouveau type de ressources électroniques dont la particularité est de comporter les mêmes textes dans deux ou plusieurs langues, et qui sont appelées « corpus parallèles ». Un corpus parallèle peut ainsi être défini comme une collection de documents où chaque unité du texte en langue source est mise en correspondance avec son équivalent en langue cible, au niveau des paragraphes, phrases ou mots (cf. Véronis 2000, Zimina-Poirot 2004). Très vite ont vu le jour plusieurs grands corpus parallèles intégrant essentiellement des données de langues déjà bien dotées en ressources monolingues tels l’anglais, le français, l’espagnol, le tchèque, etc. Au tout début des années 2000, le serbe n’était pas dépourvu de ressources textuelles électroniques (cf. Krstev 2008, pour un aperçu), mais aucun corpus parallèle n’était disponible pour cette langue[2].
Les premiers travaux autour de la constitution d’un corpus parallèle français-serbe faisant l’objet de cette contribution remontent à l’année 2007. A l’initiative de D. Stosic, à l’époque MCF en linguistique française et générale à l’Université d’Artois (Arras, France), et grâce à une subvention du Conseil scientifique de cette dernière, une équipe de linguistes et de spécialistes du traitement automatique des langues a entamé la réflexion sur la production d’une ressource textuelle électronique susceptible à la fois de répondre aux besoins spécifiques des membres du projet, pour la plupart linguistes, et de combler un manque dans le domaine des ressources textuelles plurilingues. Le projet initial prévoyait un volet centré sur les corpus oraux, un deuxième sur les corpus écrits spécialisés et un troisième visant la constitution d’un corpus parallèle français-serbe. Étant donné les objectifs du projet, l’équipe réunissait des enseignants-chercheurs de deux universités françaises (Lille 3 et Artois) et d’une université serbe (Université de Belgrade). Le troisième volet a été consolidé l’année suivante par une nouvelle subvention du Conseil scientifique de l’Université d’Artois, qui a permis de poser les bases méthodologiques et scientifiques d’un projet de constitution d’un corpus parallèle plus ambitieux, prévoyant l’intégration des données de l’anglais, en plus de celles du français et du serbe. Un tel choix se justifiait par l’inexistence de corpus parallèle disponible pour le serbe, ce qui pouvait être considéré au début du XXIe siècle comme une réelle entrave au développement de la linguistique contrastive prenant le serbe comme l’une des langues d’étude. Ces deux premiers financements avaient permis d’initier des échanges entre des linguistes et informaticiens français et serbes membres du projet, d’identifier les outils de traitement automatique des langues adaptés aux besoins du projet et de collecter un premier ensemble de données, relevant essentiellement de textes littéraires écrits dans une des trois langues mentionnées, et traduits dans au moins une des deux autres langues. Pour être traités dans le cadre du projet, les ouvrages originaux et leurs traductions devaient être libres de droits ou, s’ils étaient protégés, une autorisation d’utilisation dans le cadre du projet devait être obtenue au préalable des auteurs, traducteurs ou leurs ayants droits. Depuis le début du projet, une attention particulière est accordée à ces aspects juridiques dans un souci de respect des droits d’auteurs.
La coopération universitaire ainsi établie s’est poursuivie en 2010 et 2011 dans le cadre d’un projet bilatéral franco-serbe du programme PHC « Pavle Savic » de l’Egide, financé par le ministère des Affaires étrangères et européennes du gouvernement français et le ministère de la Recherche du gouvernement serbe. Si le projet, co-dirigé par D. Stosic (Université d’Artois) et D. Vitas (Université de Belgrade), impliquait les mêmes établissements d’enseignement et de recherche, l’équipe a été considérablement élargie, notamment du côté serbe. En effet, plusieurs enseignants-chercheurs et doctorants du Département d’études romanes de la Faculté de philologie de Belgrade ont à cette occasion rejoint le projet, apportant ainsi une expertise essentielle pour la constitution du corpus parallèle. L’ensemble des compétences des membres du projet a permis d’élaborer une chaîne de traitement à la fois complète et efficace allant de la numérisation des textes à l’alignement en passant par la vérification manuelle des textes numérisés, leur segmentation et leur transformation au format XML normé TEI (Text Encoding Initiative[3]). A la fin du projet, un corpus de 2.000.000 de mots a été constitué, comportant onze ouvrages et leurs traductions, cités dans le tableau ci-dessous :
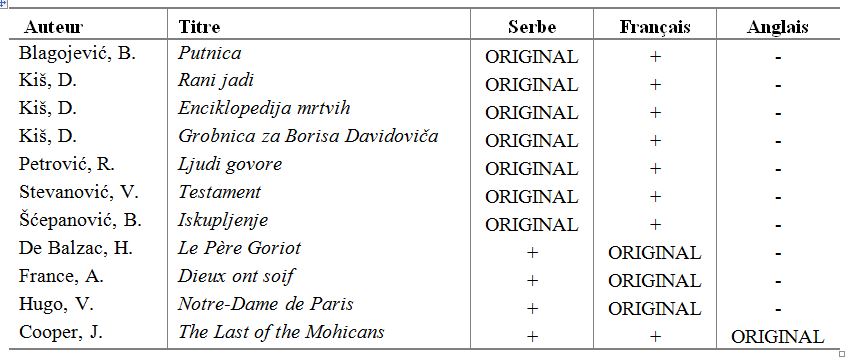
Tableau 1. Répartition des textes par langue dans la première version du corpus parallèle
Des réunions régulières organisées pendant la durée du projet ont permis non seulement des collaborations scientifiques et technologiques de haut niveau entre les organismes de recherche français et les universités serbes, mais aussi une implication importante de jeunes chercheurs, voire d’étudiants de licence et de master. Grâce à la formation par la recherche, les jeunes participants au projet ont pu acquérir des compétences qu’ils n’auraient pas pu développer dans le cadre de leur formation de base, notamment en traitement automatique des langues, en alignement de corpus et en linguistique comparée. Les deux plus jeunes auteurs de cet article ont fait partie de ce groupe d’étudiants et jeunes chercheurs[4].
Si les données collectées et alignées marquaient une avancée significative dans la constitution du corpus parallèle, pour être valorisées elles devaient être transformées en une base de données électronique interrogeable en ligne. En effet, la diffusion de la ressource au sein de la communauté scientifique et pédagogique à l'échelle nationale et internationale via une plate-forme web était la seule à garantir à la fois son utilité et son utilisation. Cette nouvelle étape a été franchie en 2015 grâce à une subvention de la Cellule Valorisation de l’Université Toulouse Jean Jaurès et du Laboratoire CLLE (UMR 5263 du CNRS), où D. Stosic a été muté en 2013[5]. En avril 2015, sur les serveurs de l’Université Toulouse Jean Jaurès a été publiée une première version d’une application web permettant l’interrogation des documents alignés, la gestion des données et l’administration des utilisateurs. Depuis, grâce à de nouveaux financements[6] et aux efforts conjoints des enseignants-chercheurs, jeunes chercheurs et étudiants de l’Université de Toulouse et de l’Université de Belgrade, le corpus parallèle, nommé ParCoLab, s’enrichit en permanence des points de vue quantitatif et qualitatif. Du fait de sa taille et de ses performances, il est aujourd’hui au cœur d’une dynamique scientifique et pédagogique très soutenue entre les établissements partenaires français et serbes, présentant un fort intérêt socio-culturel.
2. Le corpus parallèle ParCoLab: contenu, taille, fonctionnalités et usages
Comme nous l’avons dit dans la section précédente, depuis 2015, le corpus parallèle ParCoLab est développé et maintenu au sein du Laboratoire de recherche CLLE (UMR 5263, CNRS et l’Université Toulouse Jean Jaurès) en étroite collaboration avec la Faculté de philologie de l’Université de Belgrade. Le corpus est gratuitement accessible pour consultation à l’adresse : http://parcolab.univ-tlse2.fr/. Tous les documents sont structurés au format XML, normé TEI P5, et décrits par des métadonnées standardisées comme : titre, sous-titre, auteur, traducteur, éditeur, lieu d’édition, date de publication, date de création, source, langue du texte, langue de l’original, domaine, genre, nombre de mots, dérivation (original ou traduction), etc. L’alignement de type 1:1 est effectué au niveau des divisions (chapitres, sections, etc.), des paragraphes et des phrases. Un algorithme interne à la ressource effectue l’alignement en s’appuyant sur la structure des documents pour établir les correspondances d’abord au niveau des divisions, ensuite au niveau des paragraphes, puis au niveau des phrases ; la sortie est ensuite vérifiée manuellement pour garantir la qualité de l’alignement. Contrairement à de nombreux autres projets de constitution de ressources linguistiques qui privilégient les aspects quantitatifs, nous donnons la priorité à la qualité des données recueillies et des traitements effectués, ce qui exige une plus grande implication du facteur humain dans le processus du traitement.
2.1. Le contenu de la ressource
Le corpus parallèle ParCoLab est une ressource trilingue comportant des textes originaux en français, en serbe et en anglais, ainsi que leurs traductions dans une ou dans les deux autres langues. Par conséquent, on peut considérer qu’il s’agit d’une collection de trois sous-corpus ayant chacun une langue pivot différente. A l’heure actuelle, la ressource contient 11,1 millions de mots dans les trois langues, originaux et traductions confondus. Le graphique 1 donne la répartition des données selon la langue.
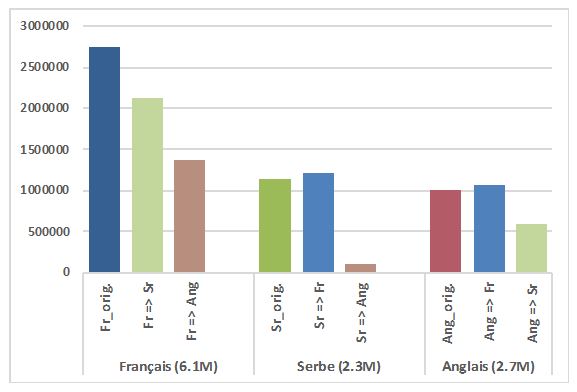
Graphique 1. Répartition des données par langue
Il est facile de constater l’accélération de l’agrandissement du corpus à partir du moment où la plateforme ParCoLab a été construite et mise en ligne : en trois ans, le corpus est passé de 2 millions à 11,1 millions de mots. Comparé au corpus initial présenté dans le tableau 1 ci-dessus, la ressource comporte actuellement 33 documents originaux français, 34 originaux serbes et 11 originaux anglais alignés avec leur traduction respective dans au moins une autre langue.
L’enrichissement quantitatif s’accompagne d’une diversification qualitative, à savoir que même si les textes littéraires ‒ les plus faciles d’accès ‒ restent majoritaires dans le corpus (87%), d’autres types de documents ont été introduits dans la base : textes juridiques, contenus des sites web, transcriptions de films, etc., comme présenté dans le tableau 2[7]. Les efforts dans ce sens continuent et de nombreux documents relevant de bien d’autres domaines seront intégrés à la base dans les mois à venir.
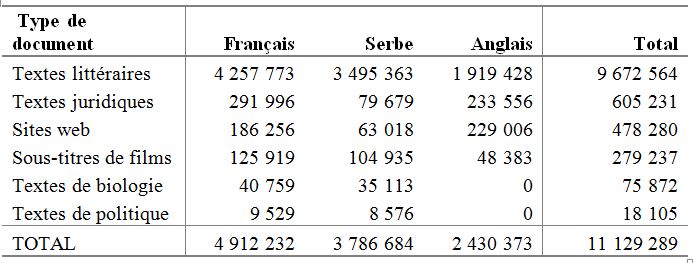
Tableau 2. Répartition des données par type de document (en nombre de mots)
Insistons ici sur le fait que l’intégration des sous-titres de films dans le corpus parallèle permet de disposer d’un échantillon inédit de lexique et de structures linguistiques propres à la langue parlée. Minutieusement travaillés dans le cadre des ateliers de traduction organisés au Département d’études romanes de l’Université de Belgrade par des enseignants et lecteurs à destination des meilleurs étudiants de français, les sous-titres apportent des solutions de traduction de très bonne qualité pour de nombreuses expressions dont le traitement dans les dictionnaires bilingues français-serbe ou serbe-français est soit inexistant soit inadéquat (cf. Marjanović et al. 2018). La ressource ParCoLab devient ainsi une alternative aux dictionnaires de plus en plus intéressante dans la mesure où certains termes relevant de l’usage oral de la langue sont souvent proscrits en lexicographie traditionnelle. A ce propos, on peut se référer à Bujas (1993), qui fait état des points critiques de la lexicographie bilingue yougoslave : manque d’actualité et de créativité de la nomenclature ; caractère prescriptif dans la sélection des entrées et dans leur traitement ; forte tendance à éviter les mots « sensibles », notamment les jurons, les mots à caractère sexuel et politique ; manque de volonté d’inclure les néologismes récents.
2.2. Plusieurs types d’annotation
Depuis la constitution de la première collection de textes alignés en 2011 (cf. Tableau 1), l’équipe du projet s’est donné comme objectif l’enrichissement du corpus avec des annotations lexicales, morpho-syntaxiques et syntaxiques. En effet, pour maximiser les possibilités d’utilisation des ressources linguistiques, il est d’usage d’associer aux différents types d’unités linguistiques (mots, groupes de mots, phrases, segments discursifs) divers attributs, qui peuvent ensuite être exploités dans l’exploration et l’analyse des textes ainsi annotés (cf. Véronis 2000). Trois niveaux sont plus particulièrement visés dans le cadre du projet :
- la lemmatisation, qui consiste à déterminer la forme canonique de chaque mot du corpus (cf. colonne 2 dans le tableau 3).
- l’annotation morpho-syntaxique, qui attribue à chaque mot une appartenance catégorielle, à savoir qu’à chaque mot est associée une partie du discours et, si pertinent, des traits morphosyntaxiques fins comme le genre, le nombre, le cas, etc. (cf. colonnes 3 et 4 dans le tableau 3).
- l’annotation syntaxique (parsing) qui consiste à déterminer la structure de la phrase et les fonctions syntaxiques (cf. colonne 5 dans le tableau 3).
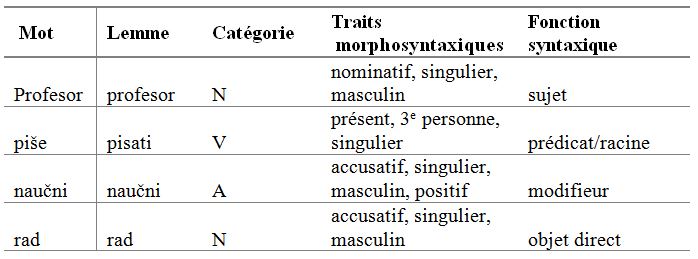
Tableau 3. Différentes couches d’annotation dans ParCoLab
L’intérêt principal de ces annotations pour un utilisateur moyen réside dans la possibilité d’effectuer des requêtes plus générales, que ce soit au niveau lexical, au niveau des classes de mots ou au niveau des fonctions syntaxiques. Par ailleurs, du fait qu’il est possible de combiner différents types d’informations dans la formulation des requêtes (par ex., pronom relatif à l’accusatif qui exerce la fonction d’objet direct), ces annotations permettent un accès facile aux données pour des phénomènes linguistiques très précis.
Aujourd’hui, seule une petite portion du corpus ParCoLab dispose des annotations citées pour les trois langues[8]. S’il est relativement facile d’annoter les documents en français et en anglais grâce à l’existence de nombreux outils suffisamment performants, tel n’était pas le cas du serbe qui reste une langue sous-dotée dans ce domaine. Les travaux récents d’A. Miletic ont cependant permis d’élaborer des modèles d’annotation automatique pour le serbe à ces trois niveaux d’analyse (cf. Miletic 2013, 2018). Ces modèles et outils, librement diffusés[9], donnent donc la possibilité de réaliser la lemmatisation, l’annotation en parties du discours et celle en fonctions syntaxiques des textes serbes (déjà intégrés ou à venir) parallèlement à l’annotation des documents français et anglais, et cela avec un degré d’exactitude élevé.
2.3. Possibilités d’interrogation du corpus parallèle
ParCoLab est un ensemble constitué de deux objets interdépendants, à savoir d’un corpus de textes originaux et traduits en français, en serbe et en anglais, et d’une application associée à une interface Web permettant l’interrogation du corpus. L’interface d’interrogation est disponible à l’adresse http://parcolab.univ-tlse2.fr/corpus/#search et aucune identification n’est requise pour y accéder. Un premier ensemble de critères affichés par défaut et organisés en trois colonnes permet de formuler des requêtes dans une seule langue ou bien dans deux ou trois langues à la fois (cf. Figure 1).
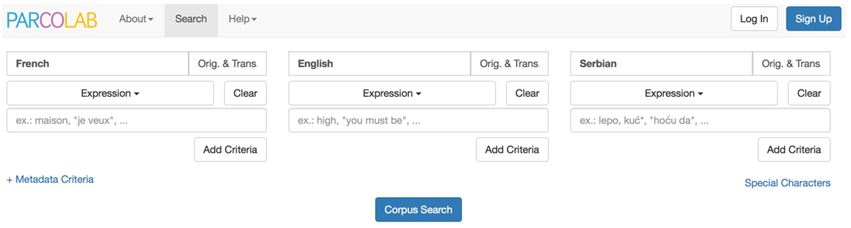
Figure 1. L’interface de consultation du corpus ParCoLab
Les sous-corpus par langue sont scindés en deux portions, à savoir que, par exemple, les textes français peuvent être des originaux ou des traductions du serbe ou de l’anglais. Cette partition est exploitée par l’interface de consultation. En effet, par défaut, les recherches portent sur l’ensemble du sous-corpus (cf. le champ ‘Orig. & Trans.’), mais il est possible de limiter des recherches aux originaux d’une des trois langues (cf. Figure 2).
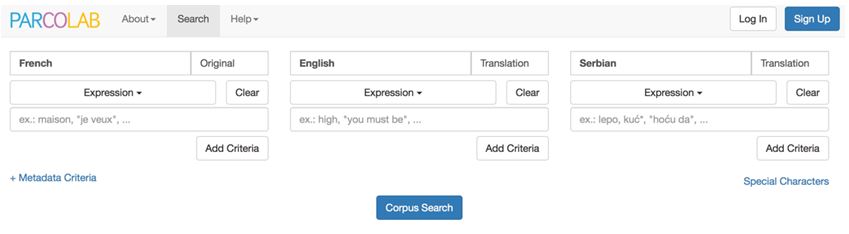
Figure 2. Limitation des recherches aux textes originaux français dans ParCoLab
Des restrictions supplémentaires sur le corpus peuvent être introduites en optant pour un ou plusieurs auteurs donnés, ou encore pour un ou plusieurs documents présents dans la base (cf. Metadata criteria, Figure 3). Une fois le corpus de travail défini, il est possible d’effectuer des requêtes simples en recherchant une expression donnée dans une des langues (ex. maison, sa maison, au fin fond du, etc.) ou bien dans plusieurs langues (cf. Figure 3). L’interface d’interrogation exploitant le moteur de recherche Elasticsearch, l’utilisation des opérateurs booléens (ex. AND, OR, NOT) et des expressions régulières (ex. . ? + * | { } [ ] ( ) " \) est possible[10].
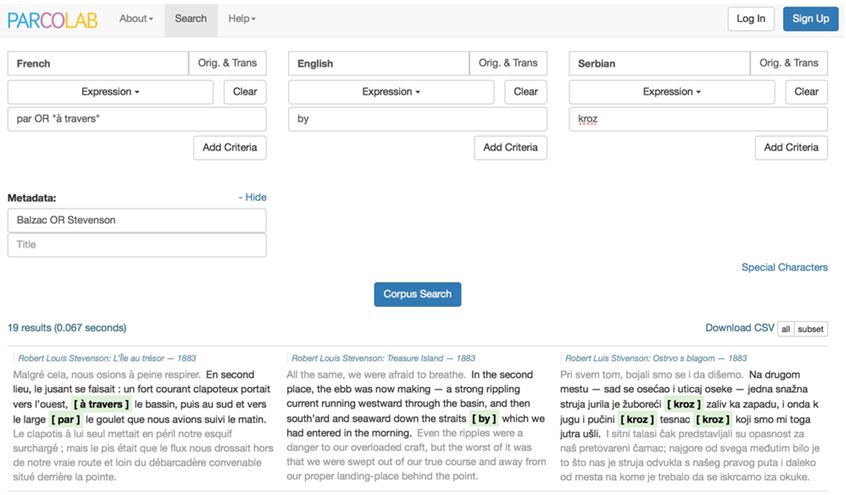
Figure 3. Un exemple de recherche simple dans ParCoLab
Il est également possible de faire des recherches plus complexes (recherche de cooccurrences, recherche avec des jokers, etc.) en ajoutant autant de champs de recherche que nécessaire pour la formulation de la requête à l’aide du bouton ‘Add criteria’.
Enfin, en choisissant Feature au lieu d’Expression dans la deuxième ligne du formulaire (cf. Figure 4), il est possible d’interroger la partie annotée du corpus par lemme (cf. champ Lemma), par catégorie morpho-syntaxique (cf. champ Any p.o.s.) ou encore par fonction syntaxique (cf. champ Any syntax) (cf. section 2.2). Là aussi, la combinaison de plusieurs critères ou de plusieurs types de critères est possible :
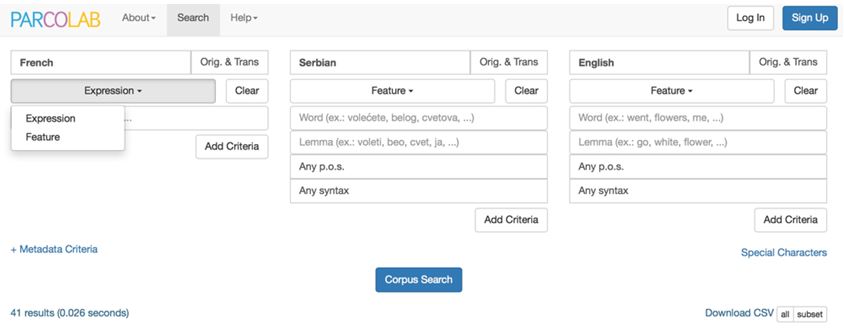
Figure 4. Un exemple de recherche complexe dans ParCoLab
Précisons pour finir que l’interface permet le rapatriement des résultats obtenus au format CSV et qu’une rubrique d’aide pour la formulation des requêtes est disponible sur le site.
Les résultats de recherche sont affichés en-dessous du formulaire de requête, disposés en trois colonnes (cf. Figure. 3). Ils sont composés de phrases comportant l’expression recherchée (ou les expressions recherchées), entourées de leurs contextes gauche et droit immédiats affichés en caractères gris clair et alignées avec les segments correspondants dans deux autres langues.
3. Applications en lexicographie bilingue
Cette façon d’afficher les résultats permet à l’utilisateur d’examiner le fonctionnement des expressions recherchées, de les comparer à ceux de leurs traductions et de repérer rapidement des équivalents de traduction, ainsi que des contextes dans lesquels ceux-ci sont employés (cf. Atkins & Rundell 2008 : 478). Étant donné que l’établissement d’équivalences est la tâche principale du lexicographe travaillant sur un nouveau dictionnaire bilingue, l’une des applications du corpus parallèle se trouve dans le domaine de la lexicographie bilingue.
3.1. De l’utilité des corpus parallèles en lexicographie bilingue
Il a déjà été démontré sans ambiguïté, sur des exemples spécifiques, que, quelle que soit la paire de langues alignées, les corpus parallèles pouvaient permettre d’extraire, entre autres, un ensemble de très bons équivalents non répertoriés dans des dictionnaires existants et facilement réutilisables en lexicographie bilingue (cf. Hartmann 1994, Roberts 1996, Roberts & Montgomery 1996, Dickens & Salkie 1996, Teubert 2002, Citron & Widmann 2006, Salkie 2008, Goossens 2012, Perdek 2012, Perko & Mezeg 2012, Zavaglia & Galafacci 2014). De même, il est généralement admis que les corpus parallèles peuvent être utiles même lorsque les textes bilingues alignés correspondant aux traductions d’un même texte source dans une troisième langue (appelé pivot) sont comparés entre eux (par exemple, le corpus français-allemand de la République de Platon, dans Teubert 2002). Considérant que l’utilisation d’un corpus parallèle peut aider le lexicographe à savoir quels équivalents ont vraiment été utilisés par des traducteurs, et dans quels contextes, ces ressources peuvent largement compenser l’intuition du lexicographe et augmenter l’objectivité du produit final.
Toutefois, bien que l’utilité des corpus parallèles ait clairement été démontrée et que la communauté métalexicographique ne remette aucunement en cause l’apport des corpus parallèles dans le domaine de la lexicographie bilingue, il n’y a pas eu, pendant une longue période, de mention de projets concrets de dictionnaires basés sur des corpus parallèles (cf. le sondage d’Atkins & Rundell 2008 : 477 à ce propos). On peut cependant citer le Dictionnaire canadien bilingue (Roberts 1996 ; Roberts & Montgomery 1996) comme seule exception. Il s’agissait en effet d’un projet monumental de dictionnaire de l’anglais et du français canadiens, mais qui n’a malheureusement pas été mené à bien et le dictionnaire n’a jamais vu le jour. Notons toutefois que même dans la fabrication de ce dictionnaire inachevé, le corpus parallèle n’a été utilisé qu’à la fin de la phase de traduction pour s’assurer qu’aucun équivalent pertinent n’avait été oublié (Roberts & Montgomery 1996 : 460).
Cette situation pourrait s’expliquer par plusieurs raisons, notamment par la faible disponibilité de corpus parallèles pour la plupart des paires de langues, par le coût élevé de constitution d’un nouveau corpus parallèle, la taille insuffisante des corpus parallèles existants ou encore la fiabilité insuffisante des traductions qu’ils contiennent (cf. Salkie 2008). Alors que les trois premiers problèmes sont plus ou moins évidents, le quatrième mérite un commentaire. En effet, il a été démontré que les mauvaises traductions pouvaient être utiles dans le processus d’élaboration de dictionnaires (cf. Marjanović 2017 : 487‒492) : la fréquence élevée de traductions erronées d’une expression donnée peut être considérée comme indice de difficultés de sa transposition dans l’autre langue, ce à quoi les lexicographes devraient accorder plus d’attention.
Par ailleurs, Atkins & Rundell (2008 : 478) soulignent que les corpus parallèles offrent trop d’attestations et qu’un examen manuel détaillé de tous les résultats du corpus ralentit inévitablement le lexicographe, ce qui n’est pas rentable pour l’éditeur. Cet obstacle est toutefois surmonté ou, du moins, considérablement atténué par de nouveaux outils d’extraction automatique d’équivalents (cf. par exemple Baisa et al., 2014, Škrabal & Vavřín 2017), qui contribuent à l’automatisation du travail lexicographique. Pour toutes ces raisons, les corpus parallèles prennent de plus en plus d’ampleur dans la lexicographie électronique (cf. Héja 2010, Lindemann 2013, Lindemann et al. 2014, Škrabal & Vavřín 2017).
Dans le but d’illustrer les apports possibles du corpus ParCoLab, dans les sections 3.2 et 3.3 nous faisons état des points faibles des dictionnaires français-serbe et montrons l’utilité du corpus dans l’élaboration de nouveaux dictionnaires.
3.2. ParCoLab comme outil de recensement des équivalents des locutions prépositionnelles
Dans cette section, nous allons montrer que la lexicographie français-serbe possède un certain nombre d’insuffisances auxquelles le corpus ParCoLab pourrait facilement remédier. Notre analyse s’appuie sur deux dictionnaires (Putanec 1995 et Jovanović 2014) qui sont censés être représentatifs du fait qu’ils dominent le paysage inerte de la lexicographie française dans l’espace ex-yougoslave. En effet, le premier est considéré comme le plus complet sur le marché étant donné qu’il couvre une vaste nomenclature de 70 000 entrées, alors que le deuxième, répertoriant 30 000 entrées, prétend refléter l’usage courant du français. Les deux dictionnaires sont principalement destinés au public serbophone natif mais, a priori, le public francophone peut également être amené à les utiliser.
S’il est un pan du lexique du français qui souffre d’un traitement incomplet dans la lexicographie français-serbe, ce sont bien les locutions prépositionnelles. Par conséquent, nous allons nous en servir pour illustrer les arguments avancés. En effet, deux défauts majeurs sont faciles à observer dans les deux dictionnaires analysés : 1) l’absence de nombreuses locutions prépositionnelles répertoriées dans les dictionnaires monolingues français de référence tels Le Petit Robert et le TLFi, 2) un traitement lexicographique inadéquat des locutions prépositionnelles relevées, que ce soit au niveau de l’identification de leurs équivalents en serbe, de leur description sémantique, de l’illustration ou de la contextualisation des emplois relevés.
En ce qui concerne le premier point, nous pouvons facilement constater qu’un grand nombre de locutions prépositionnelles ne sont pas répertoriées dans ces deux dictionnaires français-serbe (cf. Tableau 4).
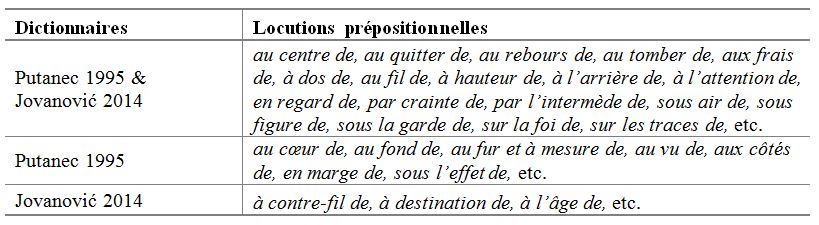
Tableau 4. Exemples de locutions prépositionnelles non-répertoriées
dans deux dictionnaires français-serbe
Face à ces locutions, un apprenant allophone ‒ qu’il soit serbophone ou francophone natif ‒ est démuni si les dictionnaires bilingues sont ses seuls outils de travail. Cet état est surprenant compte tenu de l’étendue de la nomenclature des dictionnaires analysés et de la fréquence relative de ces locutions dans l’usage contemporain. En effet, certaines de ces locutions sont très courantes et leur absence des dictionnaires bilingues n’est pas facile à justifier. Cela est d’autant plus surprenant que Putanec (1995) est un dictionnaire de grand format.
Pour traduire cette observation en termes de théorie des fonctions lexicographiques (cf. Tarp 2008), il est à noter qu’à cet égard les deux dictionnaires ne remplissent pas les fonctions primordiales d’un dictionnaire bilingue : ils ne répondent pas, d’une part, aux besoins de décodage, que cela soit dans des situations de réception d’énoncés français ou dans des situations de version pour les serbophones natifs et, d’autre part, aux besoins d’encodage dans des situations de production d’énoncés serbes pour les deux communautés linguistiques en question et de thème pour les francophones natifs. Par ailleurs, l’absence de ces locutions dans les dictionnaires ici étudiés ne permet ni aux usagers serbophones ni aux usagers francophones de bien saisir la place de ces expressions dans les deux systèmes de langue. Cela diminue considérablement l’utilité des dictionnaires en question dans l’acquisition de la langue étrangère.
Or, ce portrait général, qui se montre très disqualifiant, pourrait être atténué dans certains cas où les serbophones natifs se servent des dictionnaires bilingues pour comprendre le sens des locutions prépositionnelles. En effet, le sens des expressions du tableau 4 peut être plus ou moins accessible aux serbophones natifs selon leur degré de transparence ; s’il est relativement simple de deviner le sens des locutions au centre de, aux côtés de, en marge de à partir des éléments lexicaux qui les constituent (respectivement centre, côté, marge), la tâche s’avère ardue dans le cas des locutions aux frais de, au fur et à mesure de, sous air de et sous figure de, qui ont atteint un stade de lexicalisation plus avancé. Par conséquent, compte tenu du public serbophone cherchant à décoder le sens d’une locution en français, nous pourrions justifier l’absence des locutions de sens transparent dans Putanec (1995) et Jovanović (2014), mais il est difficile de trouver une justification pour les locutions opaques (cf. Marjanović 2017 : 497, 500‒501).
Contrairement aux dictionnaires bilingues, le corpus ParCoLab offre déjà des attestations et leurs traductions pour un bon nombre de locutions prépositionnelles du français, sans en garantir pour le moment une couverture absolue. Tel est entre autres le cas des locutions courantes aux frais de (1‒2), à hauteur de (3), à l’attention de (4), par crainte de (5‒7) :

Le recours au corpus s’avère tout aussi pertinent et intéressant dans l’identification des équivalents en serbe des locutions prépositionnelles qui sont répertoriées dans les dictionnaires bilingues. En effet, comme nous l’avons déjà signalé, les équivalents disponibles sont souvent insuffisants, présentés de manière arbitraire et sans illustrations contextualisées convenables. Nous pouvons prendre, en guise d’illustration, le traitement lexicographique dans Putanec (1995) des locutions en matière de et en fonction de. Le tableau qui suit comporte à la fois les équivalents proposés dans le dictionnaire de Putanec (1995) et ceux qui sont disponibles dans la version actuelle du corpus ParCoLab :
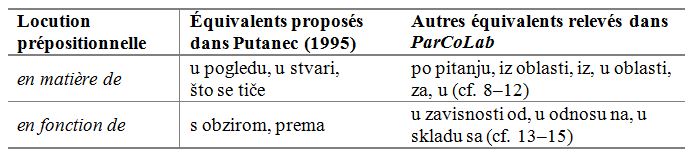 Tableau 5. Relevé des équivalents dans Putanec (1995) et dans ParCoLab pour deux locutions prépositionnelles Tableau 5. Relevé des équivalents dans Putanec (1995) et dans ParCoLab pour deux locutions prépositionnelles
Le tableau 5 montre que le corpus parallèle ParCoLab fournit, dans les deux cas présentés, plus d’équivalents de traduction que Putanec (1995). Par ailleurs, les équivalents de Putanec (1995) sont décontextualisés et ne suffisent surtout pas à l’utilisateur francophone natif qui ne saurait pas lequel des équivalents proposés choisir ou privilégier dans un contexte précis. De même, les équivalents répertoriés dans Putanec (1995) ne répondent pas aux besoins d’encodage des serbophones natifs, ce que illustrent bien les exemples (8)‒(15) extraits de ParCoLab :

Le tableau 5 et les exemples (8) à (15) montrent également à quel point l’utilisation d’un corpus parallèle dans la lexicographie bilingue français-serbe peut être bénéfique dans une tâche de base, qui est celle de l’établissement d’équivalences. Dans la section suivante, nous esquissons une démarche pour une description lexicographique plus approfondie, fondée sur des données empiriques extraites du corpus parallèle.
3.3. Pour une description lexicographique empirique : le cas de à travers
Dans cette section, nous étudions le traitement lexicographique de la locution prépositionnelle à travers dans les deux dictionnaires introduits dans la section précédente, ainsi que dans la première édition de l’un de ces dictionnaires (Jovanović 1991) (cf. Tableau 6). Cette locution a été choisie pour deux raisons : 1) elle est polysémique, ce qui permet de voir si les dictionnaires rendent bien compte de sa structure sémantique et, si non, comment elle pourrait être mieux représentée dans un dictionnaire bilingue, et 2) son sens spatial a déjà fait objet d’une analyse contrastive français-serbe approfondie (cf. Stosic 2002, 2009), ce qui donne la possibilité de comparer les résultats de cette étude à ceux que nous avons obtenus à partir des données de ParCoLab.
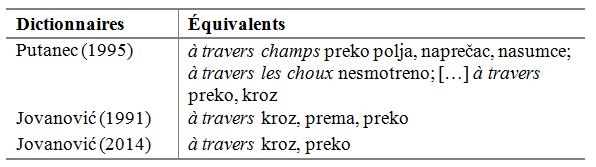 Tableau 6. Traitement lexicographique de la locution à travers dans trois dictionnaires bilingues Tableau 6. Traitement lexicographique de la locution à travers dans trois dictionnaires bilingues
Après l’examen du tableau 6, nous pouvons faire trois observations :
1. premièrement, Putanec (1995) propose à l’utilisateur non seulement la locution en question, mais aussi deux expressions figées formées à partir de celle-ci, ce qui est conforme à l’étendue de sa nomenclature. Toutefois, l’une de ces expressions n’est pas de l’usage commun (à travers les choux) et n’aurait pas dû trouver sa place dans un dictionnaire contemporain (cf. Le Petit Robert) ;
2. ensuite, Jovanović (1991) est le seul à proposer trois équivalents, dont l’un (prema – « vers ») ne figure pas dans l’édition revue et corrigée de ce dictionnaire (Jovanović 2014), ce qui pourrait nous laisser supposer que cet équivalent n’est pas adéquat. Les deux autres équivalents sont kroz et preko, mais leur ordre n’est pas le même dans les deux dictionnaires (Putanec 1995 et Jovanović 2014), ce qui pourrait nous laisser sous-entendre que ce sont des synonymes interchangeables. Or, c’est loin d’être le cas, qu’il s’agisse de leur sens de base, en l’occurrence spatial[11], ou de leurs acceptions dérivées (Piper 1977‒78, Klikovac 2000, Stosic 2002). Qui plus est, l’utilisateur serbophone natif pourrait facilement se rendre compte que ces équivalents sont, eux-mêmes, polysémiques, alors qu’aucun indicateur de sens n’y figure. Par conséquent, l’utilisation de ces dictionnaires n’est pas très éclairante pour les apprenants, quelle que soit leur langue maternelle. Il en est de même pour les utilisateurs francophones natifs, car les gloses définitionnelles qui pourraient les aider à choisir le bon équivalent font complètement défaut. Le traitement lexicographique proposé ne peut donc satisfaire que des besoins de décodage, à savoir lorsque le contexte est connu. En pareille situation, le locuteur serbophone natif saurait activer la bonne interprétation en s’appuyant sur les compétences dans sa langue maternelle.
3. enfin, le locuteur serbophone pourrait s’apercevoir facilement que les équivalents proposés par Putanec (1995) pour l’expression à travers champs n’ont pas le même sens : si le premier (preko polja) a un sens spatial transparent, les deux autres (naprečac – « soudainement », « d’un coup » ; nasumce – « au hasard ») relèveraient d’un sens plutôt idiomatique, difficile à saisir.
Afin de pouvoir juger de la pertinence des équivalents de à travers proposés dans ces trois dictionnaires, il est nécessaire de faire une étude empirique plus précise de ses emplois en contexte. Pour y aboutir, nous utilisons deux sources de données : l’étude contrastive de Stosic (2002) et une extraction du corpus parallèle ParCoLab. L’étude de Stosic (2002) est fondée sur un échantillon plus restreint composé de 103 occurrences de la locution en question, extraites manuellement d’une dizaine de romans français traduits en serbo-croate, alors que l’extraction automatique de ParCoLab nous permet d’en analyser 339 occurrences dans des phrases traduites en serbe. Grâce à ces nouvelles données, nous disposons d’un éventail beaucoup plus représentatif de contextes d’emploi de la locution à travers, ainsi que d’une grande diversité d’équivalents possibles en serbe. La répartition des équivalents dégagés à partir de ces deux sources est présentée dans les tableaux 7 et 8 respectivement :
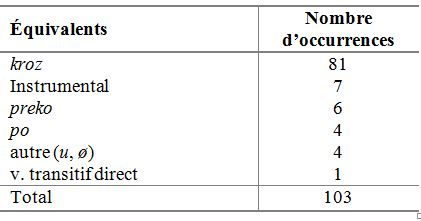
Tableau 7. Répartition des équivalents de la locution à travers
dans l’étude contrastive de Stosic (2002)
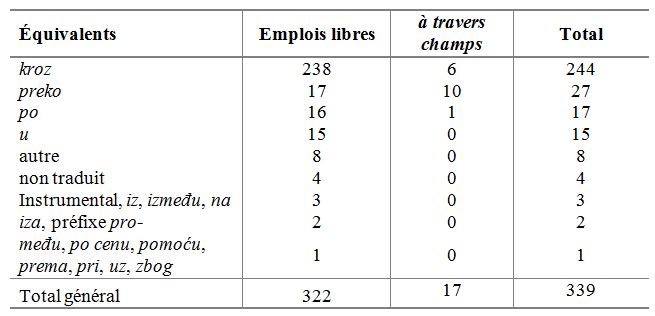 Tableau 8. Répartition des équivalents de la locution à travers dans le corpus ParCoLab Tableau 8. Répartition des équivalents de la locution à travers dans le corpus ParCoLab
Nous pouvons constater que les résultats des deux sources de données convergent largement : l’équivalent le plus fréquent et qui se trouve dans un grand nombre de contextes est kroz, suivi de preko, po, u et l’instrumental, mais ces derniers sont beaucoup moins employés que le premier, ce qui signifie que l’équivalent kroz a un haut potentiel lexicographique[12] et qu’il devrait figurer en première position dans les dictionnaires français-serbe. Cela est déjà le cas dans Jovanović (1991) et Jovanović (2014), mais non dans Putanec (1995) qui fait figurer en tête l’équivalent au potentiel lexicographique moyen (preko), beaucoup moins employé et qui exige par ailleurs une contextualisation plus concrète.
L’examen des occurrences extraites de ParCoLab nous permet également de relever des contextes d’emploi et les sens de la locution étudiée. Il s’agit d’une locution polysémique dont la structure sémantique n’est pas explicitement présentée dans les dictionnaires français-serbe, ce qui veut dire que ces derniers ne peuvent ni satisfaire aux besoins d’encodage des francophones natifs ni être utiles dans l’acquisition de la langue étrangère. Le graphique 2 montre la répartition des sens de à travers dans la version actuelle de ParCoLab :
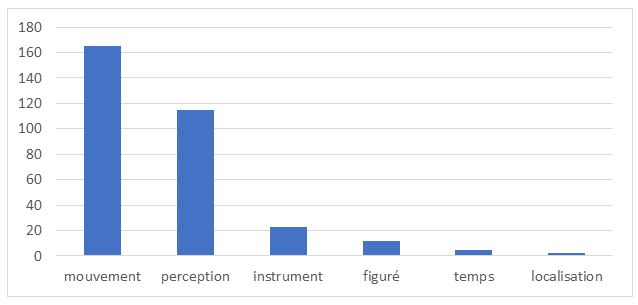 Graphique 2. Répartitions des sens de la locution à travers dans le corpus ParCoLab Graphique 2. Répartitions des sens de la locution à travers dans le corpus ParCoLab
Cette répartition est importante, car elle indique le potentiel lexicographique des sens de la locution : si la nomenclature du dictionnaire est restreinte, le lexicographe n’illustrera que les sens de mouvement et de perception, tandis que si le dictionnaire est du grand format, le lexicographe veillera à bien représenter tous les sens de la locution. Dans ce dernier cas, le lexicographe devra également tenir compte de la répartition des équivalents selon les sens. Cette répartition est présentée dans le tableau 9 :
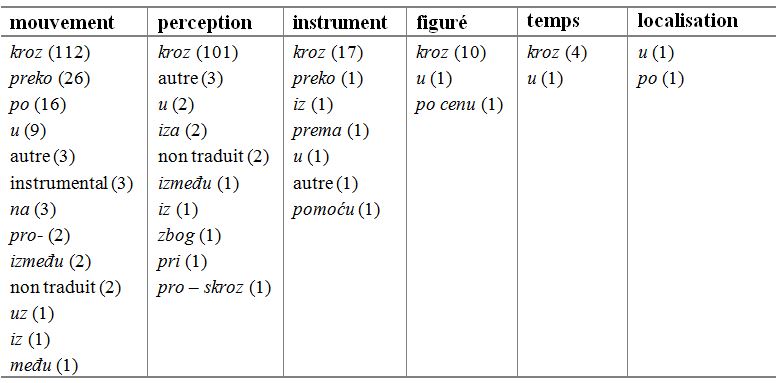
Tableau 9. Répartition par sens des équivalents de la locution à travers
Par ailleurs, comme Putanec (1995) présente l’expression à travers champs, nous avons analysé ses occurrences séparément et avons présenté les résultats dans une colonne à part dans le tableau 8. Toutes les occurrences expriment le sens de mouvement (qui est également décrit dans les dictionnaires français de référence, tels Le Petit Robert et le TLFi), ce qui laisse supposer que les équivalents de Putanec (1995) (naprečac et nasumce), qui témoigneraient d’un sens idiomatique de la locution, sont erronés. Dans le corpus ParCoLab, la préposition à travers qui entre dans la composition de cette expression est rendue en serbe par les équivalents preko (10), kroz (6) et po (1).
Si le lexicographe tient compte de toutes les considérations métalexicographiques relevées dans cette section et qu’il se fonde sur les observations des données empiriques extraites de ParCoLab, il lui est possible de faire une description lexicographique plus adéquate qui répondrait à la majorité des besoins des utilisateurs serbophones et francophones. Une telle description, pour un dictionnaire de grand format, est présentée dans le modèle suivant :

Conclusion
Dans cet article, nous avons abordé un nouvel aspect des relations franco-serbes dans le domaine des sciences humaines et sociales qui se sont développées autour de la constitution d’un corpus parallèle français-serbe-anglais. Si ces relations sont fondamentalement scientifiques et pédagogiques, leur originalité réside d’une part dans leur caractère pluridisciplinaire, d’autre part dans le fait qu’elles débouchent sur la réalisation d’une ressource électronique ayant un fort potentiel d’application dans plusieurs domaines socio-culturels : recherches scientifiques en linguistique, en didactique et en littérature, traduction, apprentissage et enseignement des langues, traductologie, lexicographie, etc. En outre, la mise à la disposition du public et des communautés scientifique et académique du corpus parallèle ParCoLab ouvre la voie à de nouvelles approches du traitement automatique du serbe ainsi qu’au développement d’outils d’aide à la traduction assistée par ordinateur.
La dynamique créée autour du projet ParCoLab a par ailleurs donné lieu à l’intensification de la coopération scientifique entre les universités françaises et serbes partenaires, à l’augmentation du nombre de productions scientifiques communes aux chercheurs français et serbes et à la formation par la recherche de nombreux étudiants de licence, de master et de doctorat. A moyen et à long terme, au travers de diverses actions de valorisation en cours et à venir, cette dynamique devrait conduire aussi à une meilleure réception de la culture serbe en France et à une meilleure réception de la culture française en Serbie, et ceci dans toute leur diversité.
Références bibliographiques
Atkins, S.B.T., Rundell, M. (2008), The Oxford Guide to Practical Lexicography, Oxford: Oxford University Press.
Baisa, V., Jakubíček, M., Kilgarriff, A., Kovář, V. & Rychlý, P (2014), “Bilingual word sketches: the translate button”, in A. Abel et al. (eds.), Proceedings of the 16th EURALEX International Congress, Bolzano: EURAC research, pp. 505‒513.
Bernard, P., Dendien, J., Lecomte, J. Pierrel, J.-M. (2002), « Les ressources de l'ATILF pour l'analyse lexicale et textuelle : TLFi, Frantext et le logiciel Stella », in 8èmes Journées Internationales d'Analyse Statistique des Données Textuelles JADT, pp. 137-149, <http://lexicometrica.univ-paris3.fr/jadt/jadt2002/PDF-2002/bernard_dendien_lecomte_pierrel.pdf>
Bujas, Ž. (1993), „Četveromjesečno S (dnevnik leksikografa)”, in R. Filipović, B. Finka, B. Tafra (ur.), Rječnik i društvo, Zagreb : Hrvatska akademija znanosti i umjetnosti, pp. 39‒45.
Citron, S., Widmann, T. (2006), “A Bilingual Corpus for Lexicographers”, in E. Corino et al. (eds.), Proceedings of the 12th EURALEX International Congress, Torino: Edizioni dell’Orso, pp. 251‒255.
Dickens, A., Salkie, R. (1996), “Comparing Bilingual Dictionaries with a Parallel Corpus“, in M. Gellerstam et al. (eds.), Proceedings of the 7th EURALEX International Congress, Göteborg: Göteborg University, pp. 551–559.
Goossens, D. (2012), “Translation equivalents in translation corpora and bilingual dictionaries: the case of approximators in English and French”, in R. Vatvedt Fjeld, J.M. Torjusen (eds.), Proceedings of the 15th EURALEX International Congress, Oslo: University of Oslo, pp. 514‒522.
Hartmann, R.R.K. (1994), “The Use of Parallel Text Corpora in the Generation of Translation Equivalents for Bilingual Lexicography”, in W. Martin et al. (eds.), Proceedings of the 5th EURALEX International Congress, Amsterdam: Vrije Universiteit, pp. 291‒297.
Héja, E. (2010), “The Role of Parallel Corpora in Bilingual Lexicography”, in N. Calzolari et al. (eds.), Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valetta: European Language Resources Association (ELRA), pp. 2798–2805.
Klikovac, D. (2000), Semantika predloga, Beograd: Filoloski fakultet.
Krstev, C. (2008), Processing of Serbian. Automata, Texts and Electronic Dictionaries, Belgrade: Faculty of Philology of the University of Belgrade.
Lindemann, D. (2013), “Bilingual Lexicography and Corpus Methods. The Example of German-Basque as Language Pair”, Procedia – Social and Behavioral Sciences, 95, pp. 249‒257.
Lindemann, D., Manterola, I., Nazar, R., San Vicente, I. & Saralegi, X. (2014), “Bilingual Dictionary Drafting. The example of German-Basque, a medium-density language pair”, in A. Abel et al. (eds.) Proceedings of the 16th EURALEX International Congress, Bolzano: EURAC research, pp. 563‒576.
Marjanović, S. (2017), Poredbene frazeme s komponentom comme/kao u francuskom i srpskom jeziku, thèse de doctorat, Belgrade: Faculté de philologie.
Marjanović, S., Stosic, D., Miletic, A. (2018), “A Sample French-Serbian Dictionary Entry based on the ParCoLab Parallel Corpus”, in S. Krek et al. (eds), Proceedings of the XVIII EURALEX International Congress: Lexicography in Global Contexts, Ljubljana: Ljubljana University Press, Faculty of Arts, pp. 423‒435
Miletic, A. (2013), Annotation semi-automatique en parties du discours d’un corpus littéraire serbe, mémoire de master 2, Lille: Université Lille 3 – Charles de Gaulle.
Miletic, A (2018), Un treebank pour le serbe : constitution et exploitations, thèse de doctorat, Toulouse: Université Toulouse Jean Jaurès.
Perdek, M. (2012). Lexicographic potential of corpus-derived equivalents. The case of English phrasal verbs and their Polish equivalents. In: R. Vatvedt Fjeld, J.M. Torjusen (eds.) Proceedings of the 15th EURALEX International Congress. Oslo: University of Oslo, pp. 376‒388.
Perko, G., Mezeg, A. (2012), „Uporaba francosko-slovenskega vzporednega korpusa pri slovarski analizi nekaterih mejnih področij idiomatike”, in M. Šorli (ur.), Dvojezična korpusna leksikografija: slovenščina v kontrastu: novi izzivi, novi obeti, Ljubljana: Trojina, zavod za uporabno slovenistiko, pp. 12‒34.
Piper, P. (1977‒1978). „Obeležavanje prostornih odnosa predloško-padežnim konstrukcijama u savremenom ruskom i savremenom srpskohrvatskom jeziku”, Prilozi proučavanju jezika, 13‒14, Novi Sad: Institut za južnoslovenske jezike Filozofskog fakulteta u Novom Sadu.
Roberts, R., Montgomery, C. (1996), “The Use of Corpora in Bilingual Lexicography”, in M. Gellerstam et al. (eds.), Proceedings of the 7th EURALEX International Congress, Göteborg: Göteborg University, pp. 457‒464.
Roberts, R. (1996), “Parallel-Text Analysis and Bilingual Lexicography”. Accessed at: http://www.dico.uottawa.ca/articles-fr.htm. [01/12/2017]
Salkie, R. (2008), “How can lexicographers use a translation corpus?”, in X. Richard et al. (eds.), Proceedings of The International Symposium on Using Corpora in Contrastive and Translation Studies (UCCTS 2008), Hangzhou: Zhejiang University. Accessed at: http://www.lancaster.ac.uk/fass/projects/corpus/UCCTS2008Proceedings/papers/Salkie.pdf. [01/12/2017]
Stosic, D. (2002), « Par » et « à travers » dans l’expression des relations spatiales: comparaison entre le français et le serbo-croate, thèse de doctorat, Toulouse: Université de Toulouse-Le Mirail.
Stosic, D. (2009), « Comparaison du sens spatial des prépositions à travers en français et kroz en serbe », Langages, 173, pp. 15‒33.
Škrabal, M., Vavřín, M. (2017), “The Translation Equivalents Database (Treq) as a Lexicographer’s Aid”, in. I. Kosem et al. (eds.), Electronic lexicography in the 21st century. Proceedings of eLex 2017 conference, Brno: Lexical Computing CZ, pp. 124‒137.
Tarp, S. (2008), Lexicography in the Borderland between Knowledge and the Non-Knowledge, Tübingen: Max Neiemeyer Verlag.
Teubert, W. (2002), “The role of parallel corpora in translation and multilingual lexicography”, in B. Altenberg, S. Granger (eds.), Lexis in contrast: corpus-based approaches, Amsterdam/Philadelphia: John Benjamins Publishing Company, pp. 189‒214.
Zavaglia, A., Galafacci, G. (2014), « Corpus, Parallélisme et Lexicographie Bilingue », in A. Abel et al. (eds), Proceedings of the 16th EURALEX International Congress, Bolzano: EURAC research, pp. 587‒597.
Zimina-Poirot, M. (2004), Approches quantitatives de l’extraction de ressources traductionnelles à partir de corpus parallèles, thèse de doctorat, Paris: Université de la Sorbonne nouvelle – Paris 3.
Jovanović, S. A. (1991), Francusko-srpskohrvatski rečnik, Beograd: Prosveta.
Jovanović, S. A. (2014), Francusko-srpski rečnik, redaktori S. Marjanović i Jelena Mijatović, Beograd: Prosveta.
Le Petit Robert de la langue française, <https://www.lerobert.com> [02/04/2018]
Putanec, V. (1995), Francusko-hrvatski rječnik, Zagreb: Školska knjiga.
Trésor de la langue française informatisé, <http://atilf.atilf.fr/> [17/03/2018]
Дејан Стошић, Саша Марјановић, Александра Милетић
ПАРАЛЕЛНИ КОРПУС PARCOLAB И ДВОЈЕЗИЧНА
ФРАНЦУСКО-СРПСКА ЛЕКСИКОГРАФИЈА: ОПИС И ПРИМЕНА
Сажетак : У овоме раду се представља научна и стручна сарадња више француских универзитета и једног факултета из Србије око пројекта израде француско-српско-енглескога паралелног корпуса ParCoLab. Реч је о новом текстуалном ресурсу који је доступан преко интернета од 2015. године и који је већ нашао примену у области аутоматске обраде природних језика те настави францускога и српског језика у инојезичној средини. Овај рад описује могућност његове примене у области двојезичне француско-српске лексикографије, и то на примеру француских предлошких израза.
Кључне речи: паралелни корпус, лексикографија, научна сарадња, предлошки изрази.
NOTES
[1] Ce travail a été réalisé dans le cadre du projet PHC Pavle Savic Corpus parallèles et lexicographie bilingue : recherche et applications (n° 36258WJ), financé par le ministère des Affaires étrangères et européennes du gouvernement français et le ministère de l’Éducation, des Sciences et du Développement technologique de la République de Serbie, et du projet Langues et cultures dans le temps et dans l’espace (n° 178002), financé par le ministère de l’Éducation, des Sciences et du Développement technologique de la République de Serbie.
[2] Le premier corpus de ce type avec les données du serbe a en effet été réalisé en 2004 dans le cadre du projet MultextEast, mais il comportait un seul ouvrage aligné dans plusieurs langues dont le serbe ‒ 1984 d’Orwell et il n’était pas destiné à une utilisation grand public (cf. Krstev et al. 2004). Deux ou trois autres tentatives intégrant des traductions en serbe datent des années 2005–2008 comme présentées dans Vitas & Krstev (2005, 2008), Vitas et al. (2008). Notons cependant que les ressources décrites dans ces travaux étaient produites pour et utilisées par des informaticiens et spécialistes du traitement automatique des langues, et non pour et par des linguistes.
[3] Cf. http://www.tei-c.org/.
[4] Par exemple, pendant sa maîtrise de langue et de littérature françaises à l’Université de Belgrade, A. Miletic a activement participé au projet, puis elle a fait en 2012‒2013 un master 2 en TAL à l’Université Lille 3 (cf. Miletic 2013), pour enfin soutenir une thèse autour de la création de ressources linguistiques électroniques pour le serbe en juin 2018 à l’Université Toulouse Jean Jaurès.
[5] Grâce à un accord entre l’Université d’Artois et l’Université Toulouse Jean Jaurès, le projet de constitution du corpus parallèle français-serbe-anglais a pu être poursuivi à Toulouse, au sein du Laboratoire CLLE.
[6] La liste des financements dont le projet a pu bénéficier par la suite est disponible à l’adresse : http://parcolab.univ-tlse2.fr/about/remerciements/.
[7] Nous renvoyons le lecteur au site du projet ParCoLab où il trouvera la liste complète des documents intégrés au corpus parallèle au moment de la rédaction de cet article (cf. http://parcolab.univ-tlse2.fr/about/contenu/).
[8] Il s’agit du roman Le jardin mystérieux de F. Hodgson Burnett, qui comptabilise un total de 233 000 mots dans les trois langues. S’y ajoute 101 000 mots de textes serbes du corpus ParCoSynTrain (cf. Miletic 2018).
[9] Les ressources sont disponibles à l’adresse : https://github.com/aleksandra-miletic/serbian-nlp-resources.
[10] Cf. https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html#regexp-syntax
[11] kroz – « à travers », « par » ; preko – « d’un côté à l’autre », « par-dessus ».
[12] M. Perdek (2012) distingue quatre niveaux de potentiel lexicographique ‒ haut, moyen, bas et zéro, où le potentiel lexicographique est entendu comme la possibilité qu’un équivalent de traduction soit repris comme équivalent lexicographique. Le haut potentiel lexicographique caractérise des équivalents idéaux qui peuvent être utilisés dans la plupart des contextes, tandis que le potentiel lexicographique zéro est attribué à des équivalents incorrects et erronés. Les équivalents au potentiel lexicographique moyen peuvent entrer dans un dictionnaire, mais doivent être présentés de manière appropriée, car ils sont limités à des contextes spécifiques ou bien ils nécessitent des transformations syntaxiques. Les équivalents au potentiel lexicographique bas se réfèrent aux bons équivalents mais qui sont appropriés à un contexte d’emploi très spécifique.
Date de publication : octobre 2019
Date de publication : juillet 2014
> DOSSIER SPÉCIAL : la Grande Guerre
- See more at: http://serbica.u-bordeaux3.fr/index.php/revue/sous-la-loupe/164-revue/articles--critiques--essais/764-boris-lazic-les-ecrivains-de-la-grande-guerre#sthash.S0uYQ00L.dpuf
|
